Comment l’analyse sémantique propulse l’innovation
marketing et aide à comprendre les foules ?
Dans le domaine du marketing, la croyance en la toute-puissante Data s’affirme avec force : on veut tout automatiser, tout optimiser, tout décrypter et tout personnaliser grâce à des algorithmes et de la Big Data. Du coup, les marques font face à une explosion du volume de données “non structurées” qu’elles doivent classifier, et analyser pour visualiser ce qui les aidera à prendre les bonnes décisions. Automatiser, oui, mais sans intelligence ? 
Peut-on analyser efficacement les données textuelles de manière automatique ?
Dans le cadre de projet participatifs, comme des “campagnes” de co-création ou des tests de concepts, les marques récoltent des données textuelles, des images, des abréviations et émoticônes. Ces contenus non-structurés n’échappent pas au besoin d’analyse. Comment les traiter ? Le Traitement Automatique des Langages (TAL) est une solution. Cette technique permet depuis une plus d’une quarantaines d’années d’automatiser la reconnaissance des concepts (entités nommées), la classification automatique d’un document, l’analyse du sentiment et des émotions. Toutefois, les approches classiques de TAL ont montré leurs limites avec l’accélération des données générées par les écosystèmes digitaux (forums, sites et plateformes, où les utilisateurs produisent de très grands volumes de données). En effet, ces approches (TAL) nécessitent que des experts, de profil infolinguiste, passent énormément de temps pour énumérer manuellement des “règles”. De plus, les systèmes obtenus nécessitent de privilégier soit le nombre d’annotations produites (pour lutter contre le silence), soit leur qualité (pour éviter d’avoir des résultats “bruités”). En d’autres termes, il fallait choisir entre un système produisant beaucoup de données (mais éventuellement bruitées) et un autre donnant des résultats de qualité (mais en trop petite quantité). Pour lever ces limites, les techniques d’apprentissage automatique ou de Machine Learning ont été introduites au début des années 2005 permettant d’obtenir plus rapidement de meilleurs résultats. 
L’analyse des données non structurées : un enjeu majeur pour les marques
Contrairement aux données marketing structurées, facilement classifiables et quantifiables (exemple : les résultats d’une enquête de satisfaction où l’âge est une donnée structurée car les tranches d’âge sont déterminées a priori), les données non structurées (ex : données textuelles) sont complexes à analyser. Les consommateurs s’expriment à travers une multitude de canaux et produisent beaucoup de verbatim sur internet. L’homme est dépassé pour agréger ces informations et les comprendre. Pour être au service de l’innovation marketing et aider les marketeurs à comprendre les marchés, ces données doivent être décryptées, classées, quantifiées. L’analyse sémantique se révèle très utile pour rendre cela possible, et l’intelligence artificielle vient au secours de la compréhension du langage humain puisqu’elle apporte de nouvelles opportunités pour faciliter le traitement et l’analyse de grands volumes de données non structurées. D’ailleurs, selon l’institut d’études Gartner, une entreprise sur deux s’intéresse de près aux innovations technologiques telle que le Machine Learning permettant la compréhension du comportement du consommateur via des masses de données textuelles (lien). 
L’intelligence artificielle au service de l’analyse sémantique
Le Machine Learning est une technologie d’intelligence artificielle permettant à la machine d’apprendre sans avoir été programmée explicitement à cet effet. Autrement dit, il s’agit de « faire apprendre » à la machine à réaliser une tâche qui nécessite classiquement de l’intelligence humaine. Pour apprendre et se développer, la machine a toutefois besoin de données à analyser et sur lesquelles s’entraîner. De ce fait, le Big Data est l’essence du Machine Learning, et le Machine Learning est la technologie qui permet d’exploiter pleinement le potentiel du Big Data Ainsi, le Machine Learning est idéal pour extraire de la valeur à partir de données textuelles massives et sans avoir besoin de compter sur un humain. Toutefois, dans le cadre de projets de co-création, cette approche automatisée, aussi avancée soit elle, ne remplace pas l’expertise métier des études : elle la complète et l’enrichit. La Data est un moyen et non une fin en soi. C’est son exploitation avisée et adaptée au contexte d’utilisation qui va lui conférer de la valeur. La Machine doit donc permettre à l’humain de se dédouaner des tâches automatisables pour lui permettre de se concentrer sur son expertise métier et apporter une forte valeur ajoutée. Aujourd’hui, on parle du concept de cobot ou « collaborative robots », il s’agit de robots d’un nouveau genre qui ont une particularité ; ils travaillent en collaboration avec un humain, dopant sa productivité en le délestant des missions les plus ingrates, éprouvantes et répétitives. Ainsi, il est crucial de souligner l’importance et la valeur ajoutée de la supervision de l’humain sur la machine. A l’ère des plateformes de co-création et des communautés de marque, les consommateurs s’expriment plus librement autour de leurs expériences sur les produits et les services, laissant libre cours à leur enthousiasme, leur mécontentement, leurs frustrations et leurs attentes, générant ainsi des grandes quantités de données (verbatim clients) qui présentent une source d’informations précieuses pour les marques. L’enjeu pour les marques est d’analyser rapidement ces données marketing pour en tirer des vérités actionnables. L’utilisation de l’intelligence artificielle dans les solutions d’analyse sémantique aide l’humain à comprendre comment exploiter cette mine d’or livrée par les consommateurs et à en tirer des plans d’action. 
L’analyse sémantique chez FANVOICE
Sur la plateforme FANVOICE, les membres de communautés de marques participent à l’innovation des entreprises en réalisant plusieurs actions. Ainsi, chaque membre de la communauté peut poster des idées ou des feedbacks et commenter les idées postées par les autres membres. Ces verbatim, une fois recueillis, représentent des centaines de milliers de mots. L’analyse sémantique de ce corpus intervient pour en valoriser les contenus : quantification et qualification des résultats, détection des zones de convergence formant les principales thématiques avec leurs poids et leurs corrélations, et identification des signaux faibles porteurs d’informations pertinentes. L’analyse aide à établir une cartographie des perceptions, attentes, et inquiétudes de la communauté et révèle d’autres enseignements que l’homme aurait difficilement identifiés dans la mesure où le signal était trop faible. La démarche permet aujourd’hui de repérer un signal faible qui nécessite une interprétation au regard de la stratégie de la marque et de ses objectifs. Cela pourrait être une opportunité de marché à saisir pour la marque, ou une zone de vigilance qui soulève des interrogations auprès de la communauté, voire une innovation de rupture. Par exemple, dans le cadre d’une campagne exploratoire organisée par une grande entreprise dans le secteur des boissons, la communauté FANVOICE a été mobilisée pour échanger autour du « moment Bière ». Les participants ont été invités à s’exprimer sur quatre thématiques pour explorer le sujet : les éléments pour un bon moment bière, les frustrations, le dernier moment bière, les idées innovantes pour le rendre encore meilleur. La campagne a permis de récolter un corpus très riche de plus de 2400 idées et commentaires, et la solution d’analyse sémantique a permis ensuite de construire la cartographie du « moment Bière idéal ». L’analyse de cette cartographie a aidé les chargés d’études à valoriser les principales thématiques abordées (avec leurs poids et les corrélations entre elles) et à les interpréter au prisme de la problématique adressée (les indispensables, les opportunistes, et les idées à fort potentiel). Enfin, il en convient d’en tenir compte, la data ne parlera pas toute seule, il faut se donner les moyens humains de la faire parler. Les 1ers indicateurs seront mis en avant automatiquement sous la forme de data viz ou de clusters, intégrant de plus en plus de corrélations, mais c’est encore l’homme qui les rend compréhensibles dans un rapport d’analyse avec des décryptages. Les temps d’analyses sont divisés par 2 à 10 suivant les projets, mais l’humain reste indispensable. Il s’agit donc encore à ce jour d’une approche “cyborg” : mi-homme, mi-machine. Bref, n’ayons pas peur de nous faire remplacer trop vite par un OS, les datas, algorithmes et autres Intelligence Artificielle vont encore avoir longtemps besoin des hommes pour être utiles et pertinents. 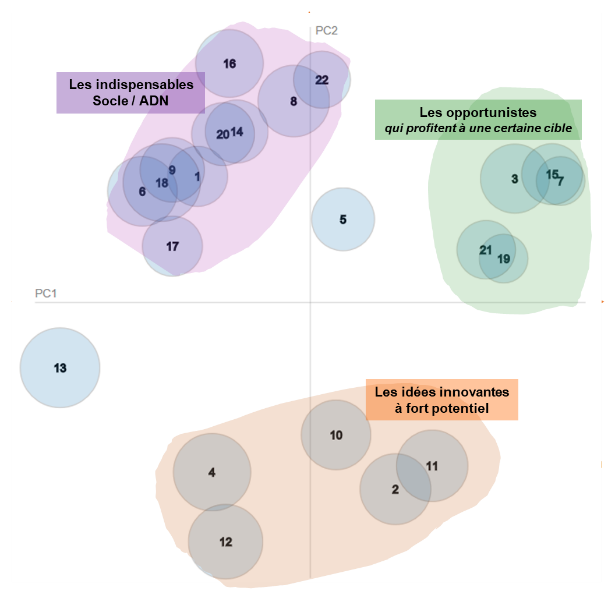

Rejoignez les marques connectées à leurs clients et collaborateurs
Nous sommes à votre disposition pour échanger sur notre univers des communautés
LES ACTUALITÉS SIMILAIRES
VOIR TOUT LES ACTUALITÉS


Déc 2024
Etudes
Études de marché : Optimisation avec l’intelligence artificielle
Révolutionner les études de marché grâce à l’intelligence artificielleLes études de marché traditionnelles sont confrontées à de nombreux défis. Les volumes de données explosent, les processus sont lents et les erreurs fréquentes. Les comportements des consommateurs sont plus variés. Ces changements rendent les approches classiques obsolètes. L’intelligence artificielle (IA) offre une solution. Elle réduit les coûts, accélère l’analyse et améliore la précision. L’IA permet de traiter des données variées et de mieux comprendre les comportements des consommateurs.Découvrez comment l’IA révolutionne les études de marché et les transforme en moteurs d’innovation.Obtenez des résultats optimaux grâce à l’IAÀ l’ère de l’hyperconnectivité, le volume de données généré quotidiennement dépasse largement les capacités humaines. Fanvoice se distingue comme une solution puissante et innovante dans les études de marché. Dotée d’outils ...

Oct 2024
Actualités
La co-création : une stratégie d’innovation clé pour accélérer la croissance de votre entreprise
Les projets d'innovation font souvent face à des défis majeurs, notamment une stratégie marketing défaillante et un manque de pertinence vis-à-vis des besoins du marché, conduisant à un taux élevé d'échecs pour les start-ups créatives. Dans un monde dans lequel seuls 10 % des projets d'innovation parviennent à se distinguer, une refonte de nos approches s'impose. Avec plus de 30 000 nouveaux produits lancés chaque année, il est alarmant de constater que 95 % d'entre eux rencontrent un destin funeste, comme le souligne Clayton Christensen de la Harvard Business School.Or, Imaginez un monde où les frontières entre consommateurs, employés et partenaires se dissipent pour laisser place à une collaboration fructueuse : c'est la magie de la cocréation ! Dans cette aventure palpitante, les entreprises plongent au cœur des besoins des consommateurs, tandis que ces derniers trouvent un espace pour exprimer librement leurs opinions et recevoir des produits et des ...

Oct 2014
Crowdsourcing & co-création
New York Times : Le célèbre journal utilise le crowdsourcing pour archiver ses publicités vintages
Se rendre sur la nouvelle plateforme participative d’archives digitales proposée par le New York Times, c’est comme faire un bond dans le passé !Le New York Times a plus de 150 ans d’existence, ses archives sont donc très nombreuses. Et même si, lorsqu’on évoque cette masse de données, on pense d’abord aux articles, il s’avère que les publicités sont aussi un excellent moyen de comprendre l’histoire. D’après Alexis Lloyd, directrice créative au sein du laboratoire de Recherche et Développement du New York Times, « Cela invite les gens à observer une part importante de notre histoire culturelle ». C’est dans cette optique que l’entreprise a décidé de lancer une plateforme d’archives digitales, identifiant toutes les publicités vintages éditées durant l’histoire du journal.Appelée Madison, en référence à la très célèbre MADISON AVENUE, berceau des plus anciennes agences publicitaires new-yorkaises, cette base d’archives réunit les ...


